DORA-yaki: DORAメトリクスダッシュボード の紹介
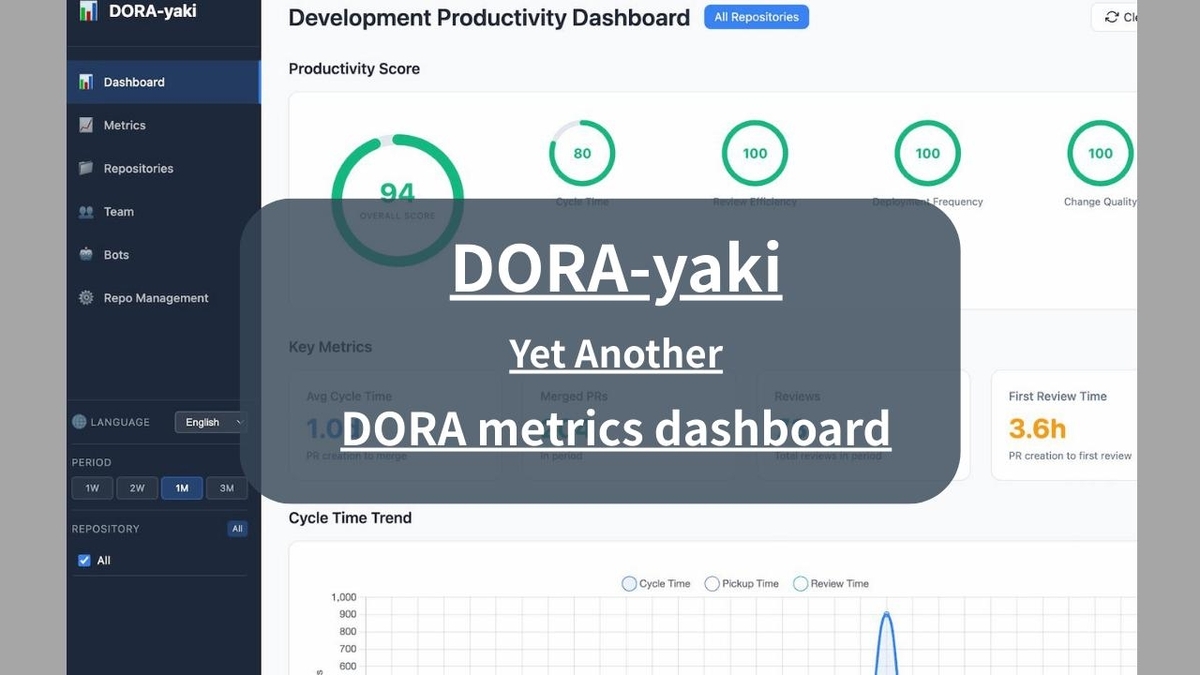
あけましておめでとうございます(2月)、羅針盤の森川です。
今回はDORAメトリクスダッシュボードツール「DORA-yaki」をOSS 公開したので簡単に紹介します。
tl;dr
GitHubのデータからDORAメトリクス + サイクルタイム分析 + 生産性スコアを可視化するダッシュボードツール「DORA-yaki」をOSSとして公開しました。
GitHub PAT を作って docker compose up で動きます。
主な特徴:
- DORAメトリクス4指標(デプロイ頻度、変更リードタイム、変更失敗率、MTTR)
- サイクルタイム分析(First Commit → PullRequest(PR) Open → First Review → Approve → Merge の各区間)
- 生産性スコア(0-100のスコアリング)
- レビュー分析(レビュー回数・コメント数・レスポンスタイム)
- チーム・メンバー別分析
- ボットユーザー除外
- 多言語対応
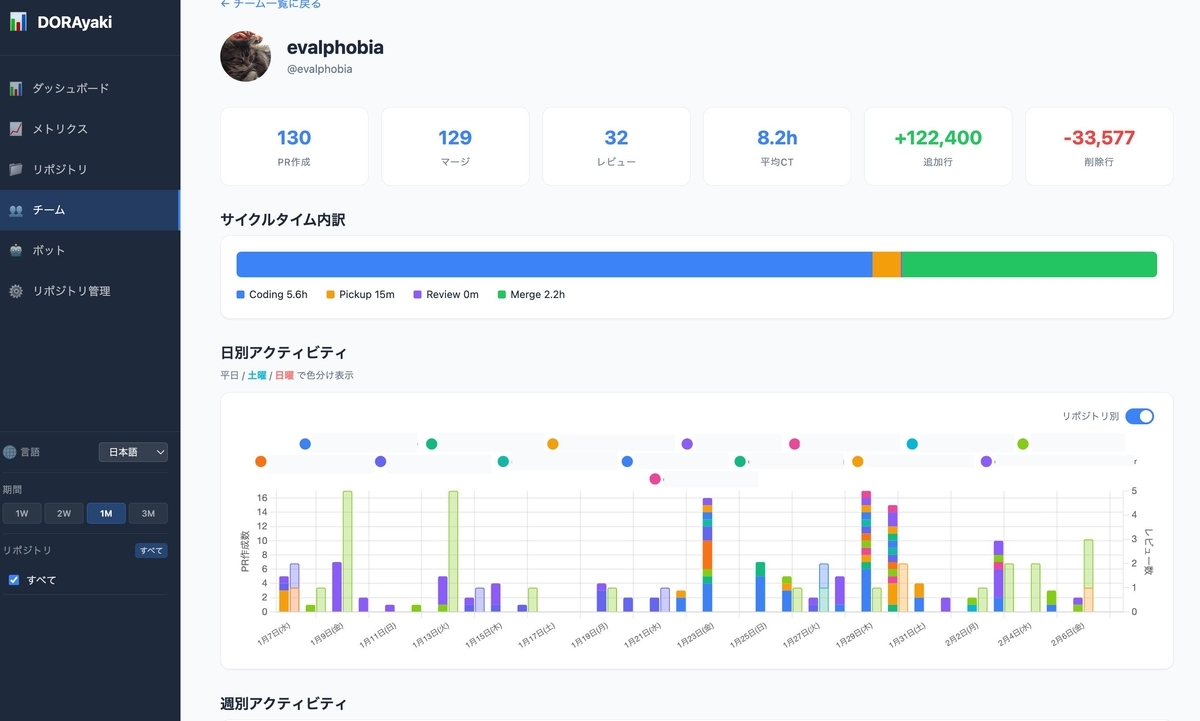
サンプルイメージ
まずはリポジトリを登録して、
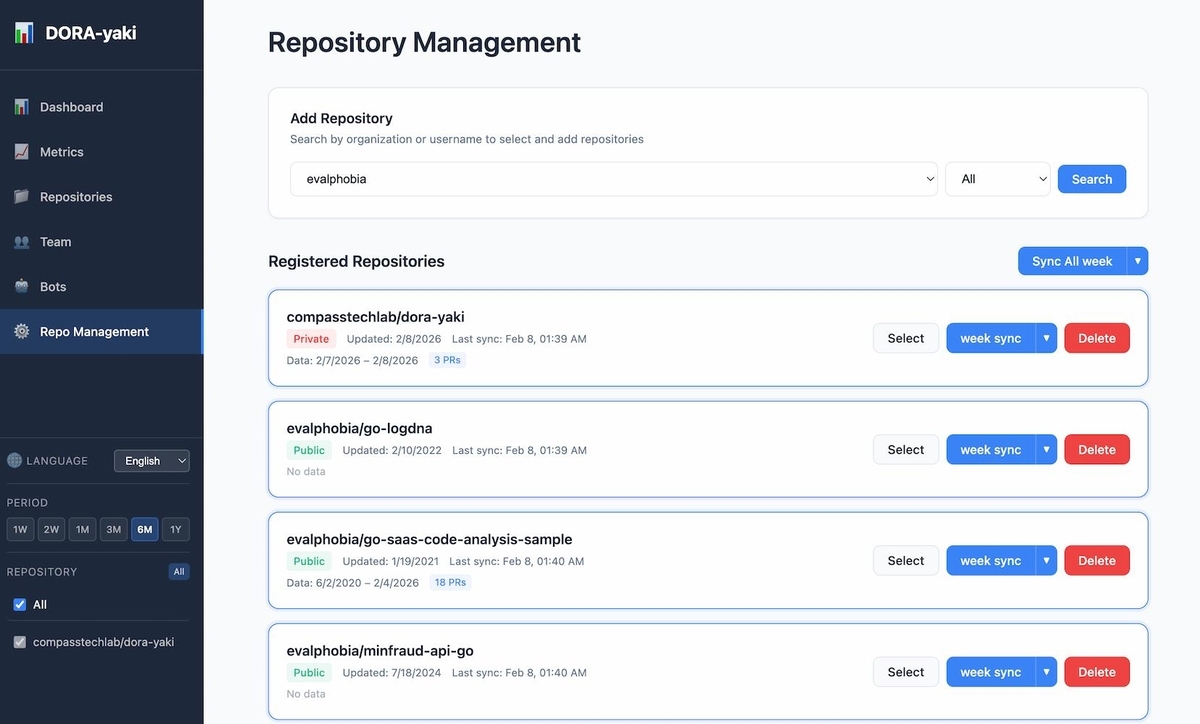
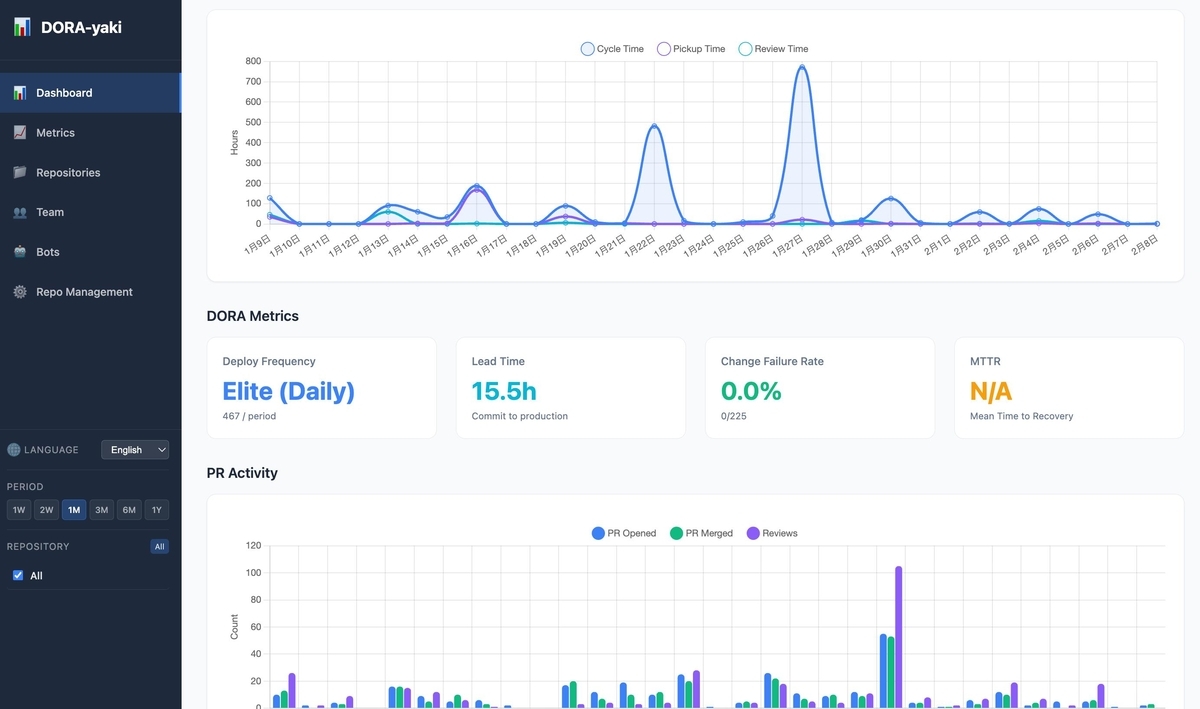
データ同期するとそれっぽいものが表示されるようになります
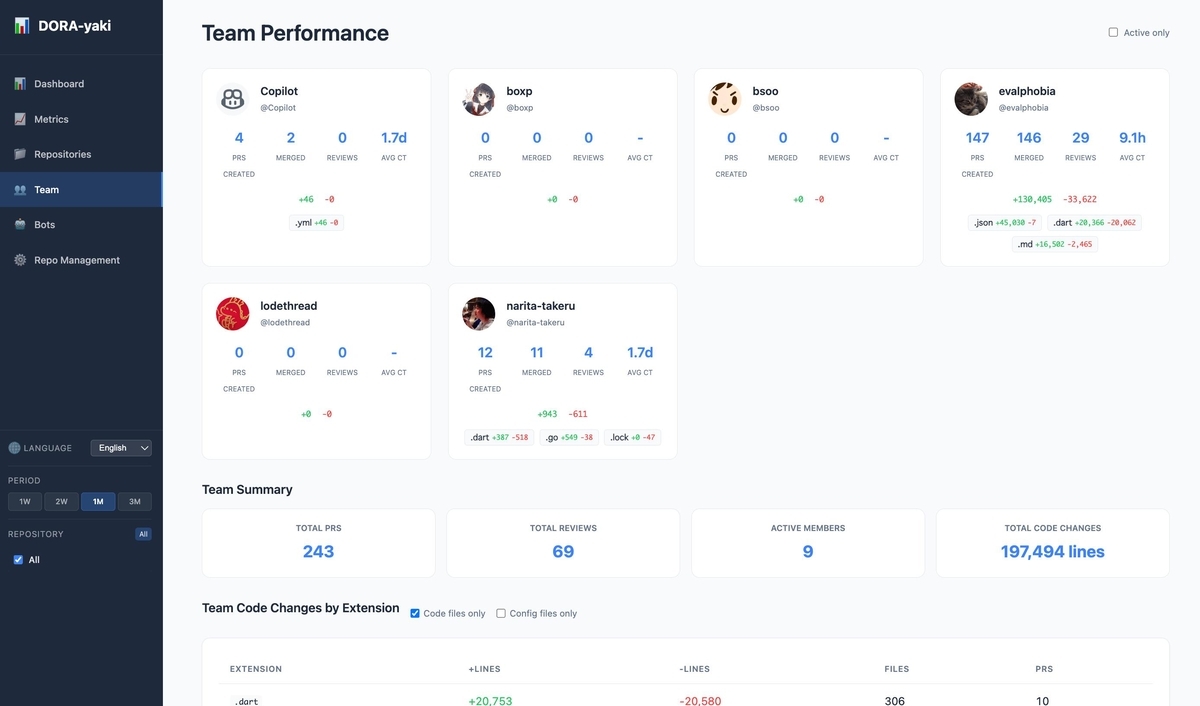
チーム一覧
詳細ページではリポジトリ別も見れます
背景
Andrej Karpathy もすなる Vibe Coding といふものを、私もしてみむとして、するなり。
x.comThere's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper…
— Andrej Karpathy (@karpathy) 2025年2月2日
ということで森川潤さんと後藤直義さんがしきりに言っている SaaS is DEAD がモノホンなのかどうか試してみました。
一応管理監督者という扱いなんですが、 コーディングマシンにもなれず、マネジメントもできず、なんか雑務ばっかしているただ日々呼吸する葦のような存在になっている気がしてきたので、 少しは管理というものをしてみようと思い、まともにDORAメトリクスを取ってみようかなと思った次第です。
DORA-yaki でできること
いわゆる開発者生産性みたいなのを可視化するためのダッシュボード的なやつです。
DORAメトリクス Four Keys
時間がある人はGoogleのDORAレポートを読んでいただきまして。 cloud.google.com
GitHubベースなので、以下のようなデータから指標を取ってます。たぶん。
| 指標 | 説明 |
|---|---|
| Deployment Frequency | デプロイ頻度(mainブランチへのマージ頻度) |
| Lead Time for Changes | 変更リードタイム(first commit → マージまでの時間) |
| Change Failure Rate | 変更失敗率(revert PRの割合) |
| MTTR (Mean Time to Recovery) | 平均復旧時間(revert PRのマージまでの時間) |
サイクルタイム分析
PRのライフサイクルを各フェーズに分解して可視化できるみたいです
First Commit ──→ PR Open ──→ First Review ──→ Approve ──→ Merge
│ │ │ │ │
└──────────────┘──────────────┘──────────────┘──────────┘
Coding Time Pickup Time Review Time Deploy Time
└────────────────────────────────────────────────────────┘
Total Cycle Time
個人的にそんな使ったこと無いんですが、PR溜まりがちとかマージ遅いとかの課題があれば見られると嬉しいんでしょうか。 Coding Timeがもう少し正確に取れると良さそうですよね。 開始時に empty commit を切るみたいなルールとか習慣を導入しないと結構ブレるので微妙な気がしていますが、 起点をブランチ作成時間とかチケットのステータス変更とか色々組み合わせられるといい感じになりそう。
生産性スコア
なんか100点満点のスコアリングなんですが、適当に重み付けして足し合わせただけっぽいので正直微妙です。
レビュー分析
レビュー回数・コメント数、レビュー反応時間、人別統計とか出してます。
チーム分析・リポジトリ分析
メンバー単位・リポジトリ単位での分析が可能です。 拡張子別の統計も付けてます。
ボットユーザー除外・分析
dependabot や renovate 等のボットユーザー(名前末尾に [bot] が付くもの)をフィルタリングしたり分析したりできます。
こいつらも日々働いてますからね。
多言語対応
日本語、英語、中国語(繁体字・簡体字)、韓国語、スペイン語、フランス語、ドイツ語の8言語に対応しています。
使い方
GitHub Personal Access Token の設定
個人、またはorgのPATを生成してください。 Repository Permissions に以下のRead権限を付けてください。
- Pull requests
- Deployments
- (Metadata)
Docker Compose で起動
簡易的に試すには docker compose で起動するのが楽です。
# GitHub Personal Access Token を設定 export GITHUB_TOKEN=github_pat_xxxxxxxxxxxx # 起動 docker compose up
ブラウザで http://localhost:7201 を開けばダッシュボードが表示されます。
クラウド環境へのデプロイ
バックエンドは Terraform を使ってもいいし、使わなくてもいいですが、 Google Cloud の DatastoreのIndex設定や IAM追加、各種APIの有効化をし、Secret Manager に GitHub Token を登録して、Cloud Functions gen2 にデプロイします。
フロントエンドは Cloud Run / Firebase Hosting / Cloudflare Pages のサンプルを各々のMakefile内に用意しているので、 そこを見ながら実行してみてください。
技術スタック
| レイヤー | 技術 |
|---|---|
| バックエンド | Go + net/http + Cloud Functions Framework |
| フロントエンド | SvelteKit (Svelte 5) + Chart.js |
| データベース | Cloud Datastore |
| インフラ | Terraform, Cloud Functions gen2 |
| コンテナ | Distroless ベースイメージ |
バックエンドは Go の net/http をベースにしていて、Cloud Functions Framework を使うことで
ローカルでは普通のHTTPサーバーとして動き、GCPではCloud Functionsとして動作するようになっています。
フロントエンドは Svelteです。jsxが無理すぎてずっとReactを避けています
注意点
今のところ認証機構やアクセス制限といった現代の必需品であるセキュリティは考慮されていません。 漢の裸一貫100%全開放状態なので、本番デプロイする場合は Cloudflare Access や IAP とかでいい感じに制限かけてください。
(そしてバグってたらごめんなさい。パッと見でしか確認してないです ;w;)
まとめと感想
きっかけはCI上のテストの最適化をしていて、細切れの待ち時間が結構あったので、 「そういえば数週間前にClaude Code Webで依頼して放置してたアレやるか」と思い出したのが始まりです。 僕の個人的なニーズを満たすものは1日程度で出来ていて、 細かいバグやドキュメント、公開のための設定で+0.5日。 そしてデバッグやこのブログを書くための見直しとかで+1.5日って感じです。
簡単なツールは本当にすぐできますが、機能を追加してバグを直している内にClaudeが内容を忘れてきて精度が落ちてきている気がしました。 例えば初期はフロントエンドを直すとバックエンドも直してくれていたのが、片方だけになっていたり、 あるバグの修正を依頼して、実際には複数のページで同じ要因でバグってたのに、最初にエラーを出した1ページだけ修正して終わらせてしまったりとかです。
コード構成自体はあまり私の好みではない部分も多いですが、それを指示するのもめんどくさくてそのままにしてます。 とりあえずニーズを満たすそこそこ動く機能のものがすぐ作れたので満足です。 SaaSがDead or Aliveなのかどうかはまだ分かっていません。
エンジニア募集
羅針盤では一緒に働いてくれるソフトウェアエンジニアや子会社CTOを募集しています。 まずはカジュアルにお話を聞いてみたいという方も歓迎です。 お待ちしております。
AWS IAM Identity Center SCIM Access Token Approaching Expiration メールへの対応備忘録 (for Google Workspace)

Google Workspaceのアカウントで AWS SSO している方向け 毎年忘れるのでブログ化しておく作戦
tl;dr
・対象者: 既にAWS SSO設定していてGoogle WorkspaceでSCIM的なプロビジョニング設定している人
AWS側の作業
- ルートアカウントでログインし、IAM Identity Centerへ
- 上部警告バナーの "Manage Token" か、Settings → Identity source タブ → Actionsボタン → "Manage provisioning"
- "Generate Token" でSCIM用のアクセストークンを発行しメモしておく
Google Workspace側の作業
- アプリ → ウェブアプリとモバイルアプリ → Amazon Web Services
- "自動プロビジョニング" を選択
- "アプリの承認" の "再承認"ボタンを押下し、先程の長いアクセストークンを入力し再認証する
無駄話
今年も12月がやってきました。師走でごわす。
12月といえばみなさん大好きクリスマス、忘年会、そして人によっては長期休暇を取って海外へバカンスいったりと羨ましい限りです。
人によっては年末年始セールに備えて入念な準備をしたり、ここしか長期メンテ時間取れないとかで、元旦あけおめDBリプレイスとか苦しい時期かもしれません。(遥か遠い目)
私にとって毎年やってくるのはサンタさんでもなまはげさんでもなく↓のメールさんです

AWS SSOや GoogleのSCIM設定とか普段触らないし、遷移もしづらいし、これ毎回やり方思い出すのにちょっとかかるんですよね。 そんなわけで2026年の私のために備忘録です。過去の自分に感謝・自画自賛する未来の私が目に浮かびます。
AWS側の作業(画像)
何はともあれAWSのルートアカウントでログインします。 そして、
- IAM Identity Centerへアクセス
- Settings → Identity source タブ → Actionsボタン → "Manage provisioning" (または上部警告赤バナー)
で移動します


そして "Generate Token" ボタンでトークンを生成します。 おそらくトークンは最大で2つまでしか同時に存在できないのでコピペし忘れたら使ってないやつを削除して再生成してください。

Google Workspace側の作業(画像)
次はGoogle Workspaceの管理者ページで、
- アプリ → ウェブアプリとモバイルアプリ
と移動し、"Amazon Web Services" を選択します。 https://admin.google.com/ac/apps/unified
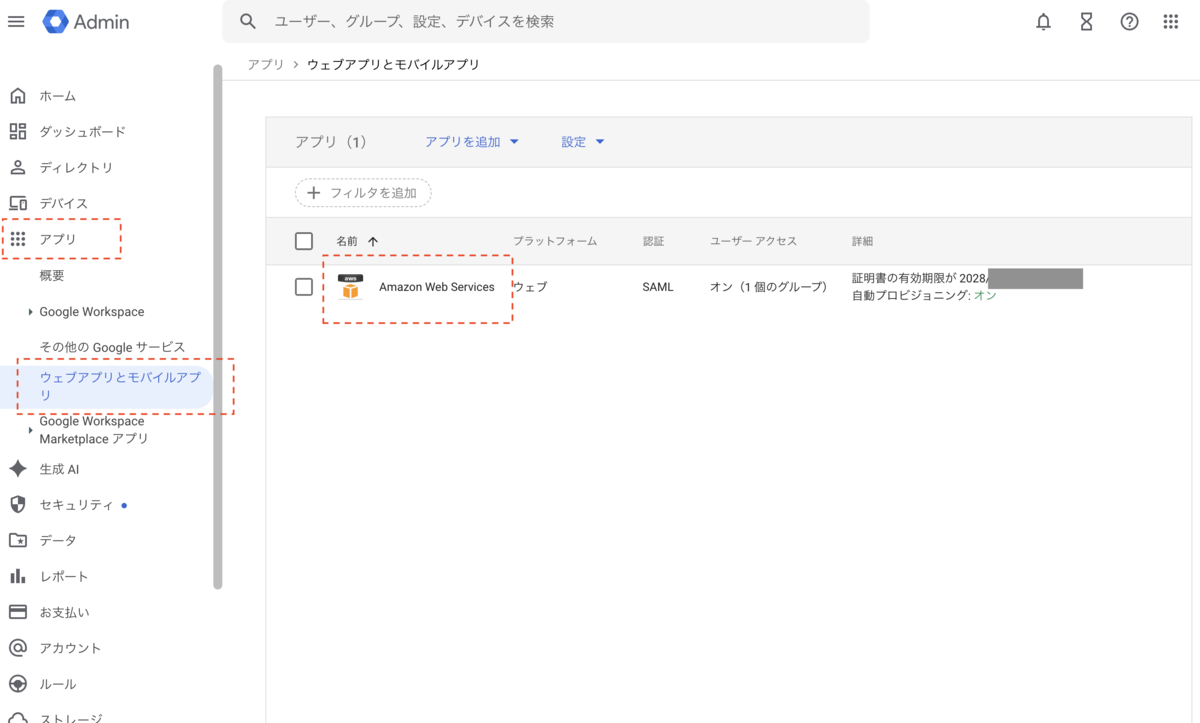
そして下部にある"自動プロビジョニング" を選択します。

最後に、"アプリの承認" の "再承認"ボタンを押下し、先程の長いアクセストークンを入力し再認証してください。

これで終了です。
成功しているかどうかマジで分かりづらいですが、Google Workspace側での属性変更やグループ追加等でデバッグすると分かります。 今回のケースでは、Google Workspace側へグループ追加 → AWS側に1~2分くらいで同期されてユーザー追加されてました。結構早いです。
来年の私へ、半裸待機大感謝してください。
Go 言語でも Vertex AI で gpt-oss を使いたい

tl;dr
現在のプロジェクトの用途では GPT-5-mini と比較しても gpt-oss-120b-maas はかなり良い感じでした。
Text 専用モデルなのが欠点ですが、用途が合えばファーストチョイスになりそうです。
Go は ↓ みたいな感じでいけます。
※ 事前に GPT OSS API Service を有効にしておく必要があります
https://console.cloud.google.com/vertex-ai/publishers/openai/model-garden/gpt-oss-120b-maas
import ( "context" "errors" "fmt" "github.com/openai/openai-go/v2" "github.com/openai/openai-go/v2/option" "golang.org/x/oauth2/google" ) const ( // OpenAI API準拠のVertexAIのエンドポイント vertexOpenAIEndpoint = "https://%s-aiplatform.googleapis.com/v1/projects/%s/locations/%s/endpoints/openapi" vertexAILocation = "us-central1" ) // 通常のOpenAI APIを使う場合はこう func ChatCompletionByOpenAI(ctx context.Context) error { cli := openai.NewClient() // OPENAI_API_KEY のAPIキーが自動で使われる messages := []openai.ChatCompletionMessageParamUnion{ openai.SystemMessage("あなたは犬です"), openai.UserMessage("猫が飼いたいです"), openai.UserMessage("猫を飼ってもいいですか?"), } params := openai.ChatCompletionNewParams{ Model: "gpt-5-mini", Messages: messages, } // OpenAIへリクエスト resp, err := cli.Chat.Completions.New(ctx, params) // エラーチェック switch { case err != nil: return err case len(resp.Choices) == 0: return errors.New("no choices") case resp.Choices[0].Message.Content == "": return errors.New("empty content") } data := map[string]any{ "model": "gpt-5-mini", "content": resp.Choices[0].Message.Content, "total_tokens": resp.Usage.TotalTokens, "prompt_tokens": resp.Usage.PromptTokens, "completion_tokens": resp.Usage.CompletionTokens, } fmt.Printf("OpenAI API Result: %+v\n", data) // => わん!猫が飼いたいんだね、いいと思うワン!ぼく(犬)から見たポイントを教えるね。 return nil } // Vertex AI のOpenAI APIを使う場合はこう func ChatCompletionByVertexAIGPTOSS(ctx context.Context) error { // GCPのOAuth認証を利用してアクセストークンを取得し、APIキーとして使う credentials, err := google.FindDefaultCredentials(ctx) if err != nil { return err } token, err := credentials.TokenSource.Token() if err != nil { return err } // クライアントを作成(BaseURLとAPIキーを設定) baseURL := fmt.Sprintf(vertexOpenAIEndpoint, vertexAILocation, "stay-operation-dev", vertexAILocation) cli := openai.NewClient(option.WithBaseURL(baseURL), option.WithAPIKey(token.AccessToken)) messages := []openai.ChatCompletionMessageParamUnion{ openai.SystemMessage("あなたは犬です"), openai.UserMessage("猫が飼いたいです"), openai.UserMessage("猫を飼ってもいいですか?"), } params := openai.ChatCompletionNewParams{ Model: "openai/gpt-oss-120b-maas", Messages: messages, } resp, err := cli.Chat.Completions.New(ctx, params) // エラーチェック switch { case err != nil: return err case len(resp.Choices) == 0: return errors.New("no choices") case resp.Choices[0].Message.Content == "": return errors.New("empty content") } data := map[string]any{ "model": "gpt-oss-120b-maas", "content": resp.Choices[0].Message.Content, "total_tokens": resp.Usage.TotalTokens, "prompt_tokens": resp.Usage.PromptTokens, "completion_tokens": resp.Usage.CompletionTokens, } fmt.Printf("Vertex AI API Result: %+v\n", data) // => ワン!もちろん、猫を飼うのは大歓迎だよ!🐱 return nil }
背景・小話
私は安くて早くて美味しいものが好きです。

目線的なものを付けてみましたが、2 本の線も3本の線になるという話が思い起こされます。
頭の良い人たちは目の付け所がシェイピーですね。
gpt-oss もみなさん騒いでらっしゃって、私も安くて早くてエコで賢いということで使いたいなと思ってました。
ちょうど現在のプロジェクトで Vertex AI の Gemini を使っていたんですが、API で Structured Output(指定の JSON 形式での出力固定)を使うと ゴミ ちょっと変なレスポンスばっかだし、
速度もめちゃくちゃ遅くなって使い勝手が悪いので困っていました。
そこで GPT-5(mini) にリプレイスしてみたら動作が安定して 2~3 倍くらい早くなりました。しかも安い。
人間は一度いいものを体験してしまうと元の生活には戻れないものです。GPT-5 でも改善して良かったんですが、さらに早く安くなるというのであれば試してみたくなります。
Amazon Bedrock で使えるみたいなのは知ってたんですが、GCP でももしかして使えるのか? と思ってみてみたら使えて安心しました。
https://console.cloud.google.com/vertex-ai/publishers/openai/model-garden/gpt-oss-120b-maas
ただサンプルコード表示を見ると curl での例しか無くてちょっと困りました。
どうすればええねん。
ENDPOINT=us-central1-aiplatform.googleapis.com
REGION=us-central1
PROJECT_ID="YOUR_PROJECT_ID"
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" https://${ENDPOINT}/v1/projects/${PROJECT_ID}/locations/${REGION}/endpoints/openapi/chat/completions \
-d '{"model":"openai/gpt-oss-20b-maas", "stream":true, "messages":[{"role": "user", "content": "Summer travel plan to Paris"}]}'
既存の Gemini 実装では google.golang.org/genai を使っていたので、これが使えるのかもと思って試してました。
それっぽい箇所もあって色々試してみたんですがなんか動きませんでした。
https://github.com/googleapis/go-genai/blob/18aeb1e9a4ec2e5f29ce619acdc544cd57a7ef55/transformer.go#L89-L92
よくよく見ると、通常の VertexAI 提供のモデルは projects/{project}/locations/{location}/models/{model} ですが、
OpenAI API Service の curl の例は projects/{project}/locations/{location}/endpoints/openapi/chat/completions です。
一瞬これ詰んでね? って思ったんですが、そういえば v0 の API も似たようなやり方で動かしたなと思い出しました。
そうです、VertexAI の API の提供形式ではなく、OpenAI の API の形式で BaseURL だけを GCP に変えれば OK でした。
猛暑の中、無駄な遠回りをしてしまいました。
curl サンプルの API キーの部分も Authorization: Bearer $(gcloud auth print-access-token) となってるので、Cloud Run 上でそのまま認証通せそうです。
なんかかんや試して無事に動かせました。
gpt-oss-120b-maas, gpt-5-min, gemini-2.5-flash の 3 モデルを、
既存のプロジェクトで使っている処理での実行比較をしてみると、、、

gpt-oss でさらに早くなりました。
スクショにはないですが、HTML テーブルでの表示結果や RawJSON も眺めましたが、内容も合っており、他モデルと変わりません。
(PDF 解析は出来ないので CSV 整形のみ)
本気の速度自体はちょっと早い(15~30%)くらいですが、長考する回数がかなり減って平均値が一気に早くなっている感触です。
なお Gemini は通常のタスクでは使うことが多いですが、
API として使うと細かい数字や長いハッシュ値の部分が適当になることと、構造化出力 (Response Schema)機能を使うと 2~3 倍遅くなる印象です。
さらに無効な文字列で永久ループを続けるので stopSequences 設定して途切れた JSON を補完したりとか試行錯誤してだるかったです。
とはいえ 1~2 ヶ月後にはまた改良されたモデルや新たなツールが出てきてもっと楽になることでしょう。(= 僕らの Yak Shaving はまだまだ続く)
補足
- tmc/langchaingo を使って VertexAI の OpenAI API Service を使う場合はおそらく ↓ で動くと思います(未確認)
import ( "github.com/tmc/langchaingo/llms" "github.com/tmc/langchaingo/llms/openai" ) // tl;dr のコードをベースに↓ llm, err := openai.New( openai.WithBaseURL(baseURL), openai.WithModel(modelName), openai.WithToken(token.AccessToken), )
- v0 の API を使う場合は BaseURL に
https://api.v0.dev/v1を指定するとたぶん動きます
まとめ
- テキスト専用モデルで、画像とかファイルを使わなければかなり良い。
- 安い。早い。エコ。
- VertexAI で使うと GCP の請求にまとめられるので(
予算・費用の承認がいらない)、管理が楽。
クレジット
google.golang.org/genai, github.com/openai/openai-go/v2 の HTTP リクエストのデバッグの際には https://github.com/motemen/go-loghttp を使いました。
10 年間いつもありがとうございます。
これからもよろしくお願いします。
GitHub ActionsでAmazon Q CLIによるGitHub PR Reviewを実行する
前々々回のDevin, 前々回のGemini CLI, 前回のOpenAI Codex CLIに続き、 またまたまた同じような記事です。すみません。
今回は Amazon Q CLIです。

背景・雑感
Claude Code, Devin, Gemini, Codex でコードレビューを実施しているのでもう十分やん お腹いっぱいという気持ちもあったのですが、せっかくなのでAmazon Qもやってみたいと思っていました。コードレビュー蠱毒です。
現状のAmazon Qのプレビュー版のGitHub Integrationは自動で発火する上に、細かいチューニングがしづらいので外して使ってませんでした。
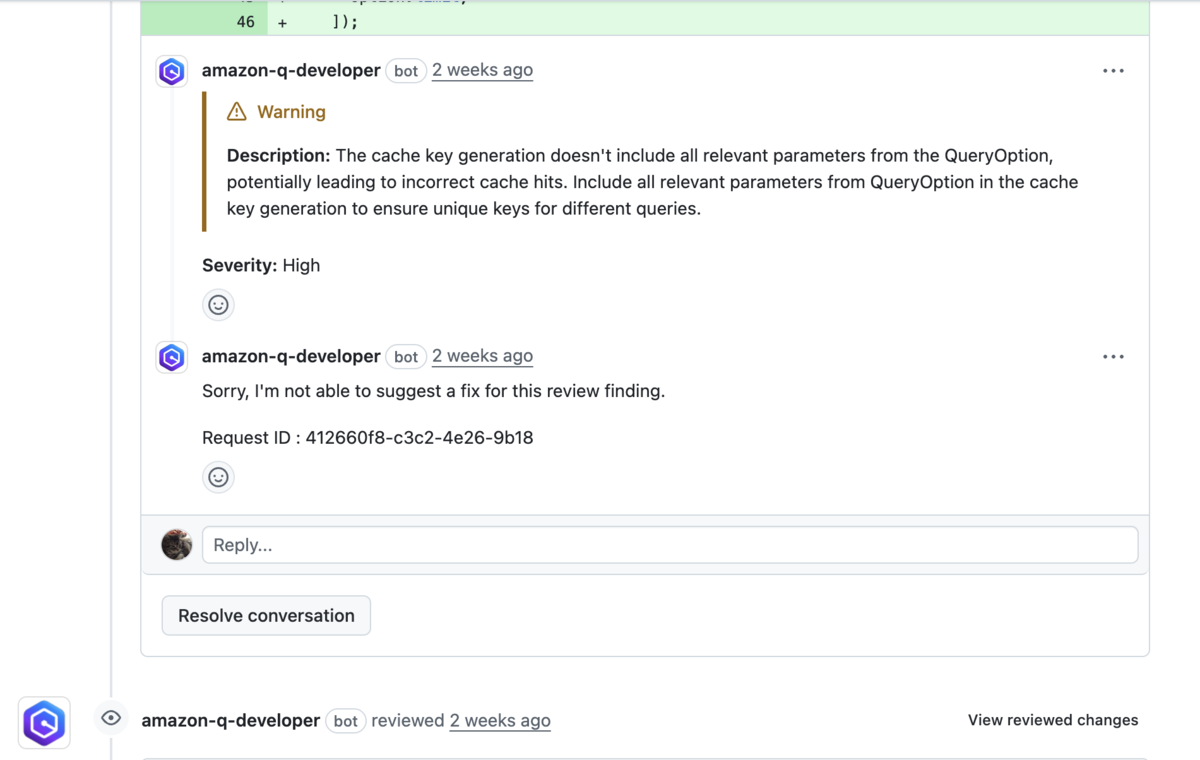
CLIはなんかインストーラーが必要だったり、認証オプション設定もなんか説明もよく分かんなかったので無理かなと思っていましたが、試行錯誤していたらなんとかできました。
正直周りで使っている話はあまり聞かないのでどうなんかなと思ってましたが、レビューはそれなりに使えそうです。 現状では Claude 4 Sonnet がデフォルトで使えるのでそれも魅力です。
tl;dr
↓のような感じで設定します
env: AMAZONQ_CLI_URL: https://desktop-release.q.us-east-1.amazonaws.com/latest/q-x86_64-linux.zip # arm64 の場合は https://desktop-release.q.us-east-1.amazonaws.com/latest/q-aarch64-linux.zip jobs: amazonq_review: runs-on: ubuntu-latest timeout-minutes: 10 steps: env: AMAZONQ_DB_DIR: /home/runner/.local/share/amazon-q steps: - name: Generate GitHub App token id: app-token uses: actions/create-github-app-token@v2 with: app-id: ${{ vars.CODE_REVIEW_APP_ID }} private-key: ${{ secrets.CODE_REVIEW_APP_PRIVATE_KEY }} - name: Checkout repository uses: actions/checkout@v4 with: token: ${{ steps.app-token.outputs.token }} - name: Cache q binary id: cache-q uses: actions/cache@v4 with: path: ~/.local/bin key: q-x86_64-linux-v1 - name: Install q if: ${{ steps.cache-q.outputs.cache-hit != 'true' }} run: | curl --proto '=https' --tlsv1.2 -sSf "${{ env.AMAZONQ_CLI_URL }}" -o "q.zip" unzip q.zip ./q/install.sh --no-confirm - name: Create SQLite database run: | touch data.sqlite3 chmod 600 data.sqlite3 sqlite3 data.sqlite3 << 'EOF' CREATE TABLE migrations ( id INTEGER PRIMARY KEY, version INTEGER NOT NULL, migration_time INTEGER NOT NULL ); CREATE TABLE history ( id INTEGER PRIMARY KEY, command TEXT, shell TEXT, pid INTEGER, session_id TEXT, cwd TEXT, start_time INTEGER, hostname TEXT, exit_code INTEGER, end_time INTEGER, duration INTEGER ); CREATE TABLE auth_kv ( key TEXT PRIMARY KEY, value TEXT ); CREATE TABLE state ( key TEXT PRIMARY KEY, value BLOB ); CREATE TABLE conversations ( key TEXT PRIMARY KEY, value TEXT ); EOF sqlite3 data.sqlite3 << 'EOF' INSERT INTO migrations (id, version, migration_time) VALUES (1, 0, 1755013634), (2, 1, 1755013634), (3, 2, 1755013634), (4, 3, 1755013634), (5, 4, 1755013634), (6, 5, 1755013634), (7, 6, 1755014426), (8, 7, 1755014426); EOF - name: Import auth_kv data from secrets run: | sqlite3 data.sqlite3 << EOF INSERT INTO auth_kv (key, value) VALUES ('codewhisperer:odic:token', '${{ secrets.AMAZONQ_AUTH_TOKEN }}'); EOF sqlite3 data.sqlite3 << EOF INSERT INTO auth_kv (key, value) VALUES ('codewhisperer:odic:device-registration', '${{ secrets.AMAZONQ_AUTH_DEVICE }}'); EOF mkdir -p ${{ env.AMAZONQ_DB_DIR }} mv data.sqlite3 ${{ env.AMAZONQ_DB_DIR }} - name: Run command env: GH_TOKEN: ${{ steps.app-token.outputs.token }} run: | git fetch origin ${{ github.base_ref }}:${{ github.base_ref }} git diff ${{ github.base_ref }} HEAD > _pr_diff.txt echo "/help" | q chat q chat -a --no-interactive -- "--command /review $(printf '%s' '${{ vars.AI_REVIEW_GUIDELINE_AMAZONQ }}')" # q で指示した _pr_comment.md が作られていることを想定している - name: Send comment to PR env: GH_TOKEN: ${{ steps.app-token.outputs.token }} run: | gh pr comment ${{ github.event.pull_request.number }} --body-file _pr_comment.md - name: Remove sqlite3 database if: always() run: rm -rf ${{ env.AMAZONQ_DB_DIR }}
補足
Amazon Q CLIの認証
軽く試した範囲では、Amazon Q CLIの認証は、OAuthのブラウザログインしかなさそうでした。IAMユーザーのアクセスキーやOIDC認証はできなさそうです。
参考
- https://builder.aws.com/content/2uLaePMiQZWbyHqmtiP9aKYoyls/automating-code-reviews-with-amazon-q-and-github-actions
- https://www.reddit.com/r/aws/comments/1lq57cl/amazon_q_login_for_cicd_github_actions/
そして認証を行うと $HOME/.local/share/amazon-q/data.sqlite3 にSQLiteのデータが保存されます。(macOSでは $HOME/Library/Application Support/amazon-q/data.sqlite3 )
ファイルサイズは40~50KBくらいになるので、S3やGCSに認証済みのSQLiteファイルを置いて使うとかでもいいんですが、実際に使っているのはこの中の auth_kv テーブルだけで、ここに認証データを入れれば Amazon Q CLIが実行できるようになります。
そこでまず SQLiteのスキーマを作成しています
touch data.sqlite3 chmod 600 data.sqlite3 # `sqlite3 data.sqlite3 ".schema";` の実行結果をそのまま利用 sqlite3 data.sqlite3 << 'EOF' CREATE TABLE migrations ( id INTEGER PRIMARY KEY, version INTEGER NOT NULL, migration_time INTEGER NOT NULL ); CREATE TABLE history ( id INTEGER PRIMARY KEY, command TEXT, shell TEXT, pid INTEGER, session_id TEXT, cwd TEXT, start_time INTEGER, hostname TEXT, exit_code INTEGER, end_time INTEGER, duration INTEGER ); CREATE TABLE auth_kv ( key TEXT PRIMARY KEY, value TEXT ); CREATE TABLE state ( key TEXT PRIMARY KEY, value BLOB ); CREATE TABLE conversations ( key TEXT PRIMARY KEY, value TEXT ); EOF
実際には、起動時に migrations テーブルにもDBマイグレーションの適用結果の内容が入っていてカラム変更が行われるためこれも入れておきます。
sqlite3 data.sqlite3 << 'EOF' INSERT INTO migrations (id, version, migration_time) VALUES (1, 0, 1755013634), (2, 1, 1755013634), (3, 2, 1755013634), (4, 3, 1755013634), (5, 4, 1755013634), (6, 5, 1755013634), (7, 6, 1755014426), (8, 7, 1755014426); EOF
あとは、 auth_kv テーブルに認証データを入れればOKです。
auth_kv は key と value の2カラムで構成されていて、 key には codewhisperer:odic:tokenと codewhisperer:odic:device-registration の2つのキーのデータがあり、 value は両方ともJSONデータが入っています。
(OIDCのtypoっぽいけど odic で合っています)
codewhisperer:odic:token の中身の例
{ "access_token": "...", "expires_at": "2025-08-13T01:00:00.797792176Z", "refresh_token": "...", "region": "us-east-1", "start_url": null, "oauth_flow": "DeviceCode", "scopes": [ "codewhisperer:completions", "codewhisperer:analysis", "codewhisperer:conversations" ] }
codewhisperer:odic:device-registration の中身の例
{ "client_id": "...", "client_secret": "<... jwt>", "client_secret_expires_at": "2025-11-10T01:00:00Z", "region": "us-east-1", "oauth_flow": "DeviceCode", "scopes": [ "codewhisperer:completions", "codewhisperer:analysis", "codewhisperer:conversations" ] }
この内、 ...:token の方だけでも動くんですが、有効期限が数時間しかなくて短いです。
中身に refresh_token も含まれているので自動更新されそうな気がするんですが、...:device-registration が無いとうまく認証トークンが更新されないようでした(PKCE?)。
これに気づかず途中まで動いていたものがいきなり動かなくなったりしてハマりました。
なので両方のデータをINSERTし、 $HOME/.local/share/amazon-q/data.sqlite3 に配置します。
env: AMAZONQ_DB_DIR: /home/runner/.local/share/amazon-q ---- sqlite3 data.sqlite3 << EOF INSERT INTO auth_kv (key, value) VALUES ('codewhisperer:odic:token', '${{ secrets.AMAZONQ_AUTH_TOKEN }}'); EOF sqlite3 data.sqlite3 << EOF INSERT INTO auth_kv (key, value) VALUES ('codewhisperer:odic:device-registration', '${{ secrets.AMAZONQ_AUTH_DEVICE }}'); EOF mkdir -p ${{ env.AMAZONQ_DB_DIR }} mv data.sqlite3 ${{ env.AMAZONQ_DB_DIR }}
変数とか
vars.CODE_REVIEW_APP_ID: GitHub AppのApp IDを入れてください- https://github.com/organizations/{your org name}/settings/apps/
secrets.CODE_REVIEW_APP_PRIVATE_KEY: GitHub AppのPrivate Keyを入れてくださいvars.AI_REVIEW_GUIDELINE_AMAZONQ: コードレビューのガイドラインを記入します- OpenAIの記事と同じように
_pr_comment.mdを作成するように指示してください。 - (
gh pr commentが直接できるかどうかめんどくさくてまだ試せていません)
- OpenAIの記事と同じように
secrets.AMAZONQ_AUTH_TOKENsecrets.AMAZONQ_AUTH_DEVICE- 上記の
codewhisperer:odic:tokenとcodewhisperer:odic:device-registrationの中身のJSONデータを入れてください
- 上記の
例示の際に分かりやすいようにベタ書きしていますが、スキーマやマイグレーションも vars で管理した方が取り回ししやすい良いかもです。
変数の更新
このままだと3ヶ月くらいで使えなくなるので、定期的に secret を更新する必要があります。 もしローカル環境に保存された認証情報を使う場合は、 GitHub ActionsのSecretを更新するためのコマンドをシェルに登録しておくと楽に更新できそうです。
function amazonq-token { # ghコマンドが使えるように envchain とかで保存した GITHUB_TOKEN を使ってください # export GITHUB_TOKEN=$(envchain my-github sh -c 'echo $GITHUB_TOKEN') local dbfile="$HOME/Library/Application Support/amazon-q/data.sqlite3" local orgname="my-org" gh secret list --org $orgname || return AMAZONQ_AUTH_TOKEN="$(sqlite3 ${dbfile} "SELECT value FROM auth_kv WHERE key = 'codewhisperer:odic:token';")" AMAZONQ_AUTH_DEVICE="$(sqlite3 ${dbfile} "SELECT value FROM auth_kv WHERE key = 'codewhisperer:odic:device-registration';")" gh secret set GLOBAL_AMAZONQ_AUTH_TOKEN --body "${AMAZONQ_AUTH_TOKEN}" --org ${orgname} gh secret set GLOBAL_AMAZONQ_AUTH_DEVICE --body "${AMAZONQ_AUTH_DEVICE}" --org ${orgname} }
Wrapping up
この子はCodexちゃんと違って素直な子でしっかり絵文字使ってくれます。偉い。かわいい。
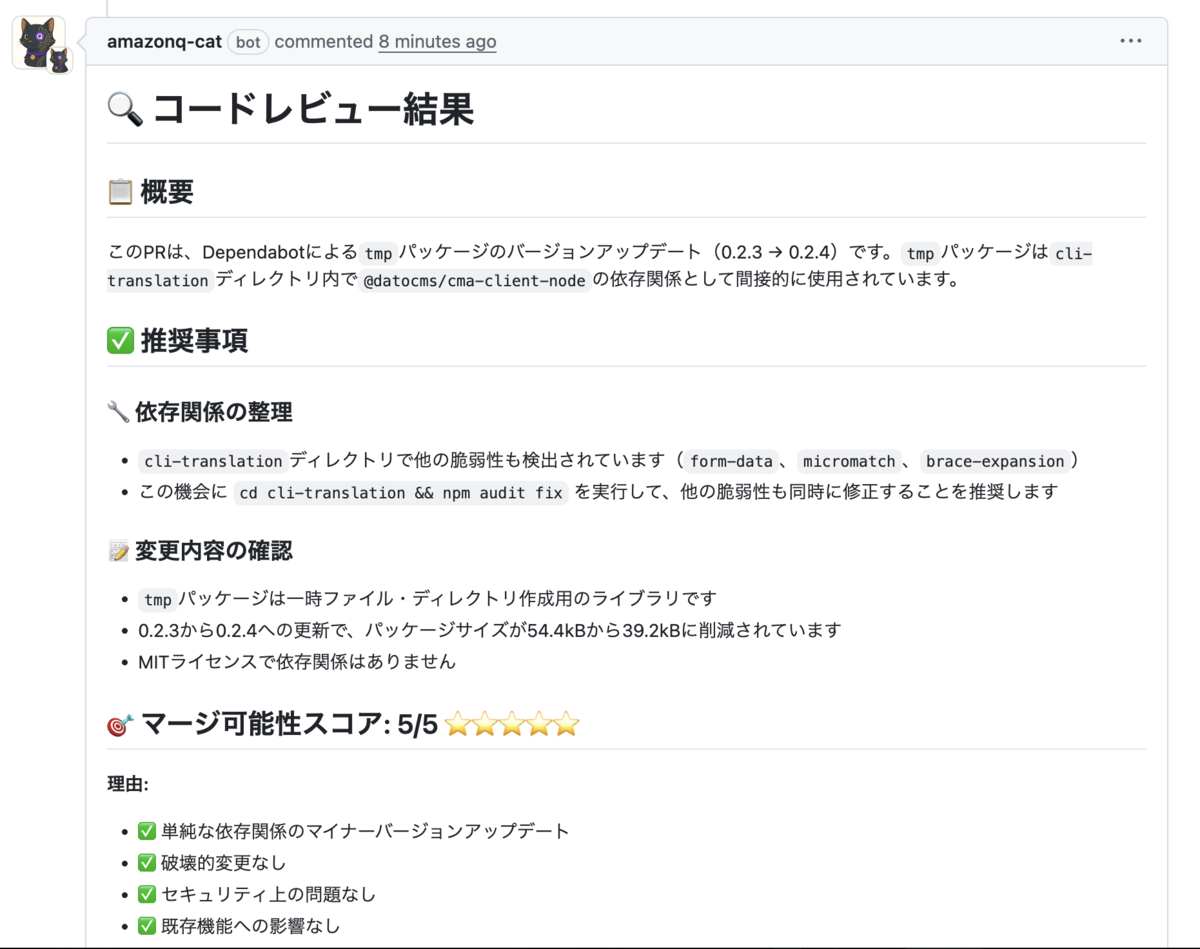
きちんと仕事してくれます。
関連
同じフォーマットで1日連続3投稿できました。
PR
エンジニアの人、助けてください。
GitHub ActionsでOpenAI Codex CLIによるGitHub PR Reviewを実行する
前々回のDevin, 前回のGemini CLIに続き、 またまた同じような記事で当てこすり続けます。 今回は OpenAI Codex CLIです。

背景・雑感
GPT-5が出たのに合わせてトライしてみました。 GPT-5は期待外れみたいな声も多いですが、期待していなかった身としては順当に安くて使いやすいので嬉しいです。
モデルも重要ですが、同じくらいツール(≒プロンプト+ワークフロー)も重要だと思っていたおりに、Codex CLIも試してみたい気持ちが高まっていたのもあり、ちょうど良いタイミングでした。 元々CodexはPro/Teamプラン限定のイメージで使えないと思っていたんですが、Codex CLIはAPI利用で自由に使えることに気づいてしまいました。思い込みって怖いですね。
tl;dr
↓のような感じで設定するだけ
jobs: openai_review: runs-on: ubuntu-latest timeout-minutes: 10 steps: # GitHub App を使う場合は↓、使わない場合は GITHUB_TOKEN を使う(おそらくpermission設定は必要) - name: Generate GitHub App token id: app-token uses: actions/create-github-app-token@v2 with: app-id: ${{ vars.CODE_REVIEW_APP_ID }} private-key: ${{ secrets.CODE_REVIEW_APP_PRIVATE_KEY }} - name: Checkout repository uses: actions/checkout@v4 env: token: ${{ steps.app-token.outputs.token }} - name: Install pnpm uses: pnpm/action-setup@v4 with: version: 10 run_install: false - name: Setup Node uses: actions/setup-node@v4 - name: Install codex run: | pnpm add -g @openai/codex - name: Run command env: GH_TOKEN: ${{ steps.app-token.outputs.token }} OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }} run: | git fetch origin ${{ github.base_ref }}:${{ github.base_ref }} git diff ${{ github.base_ref }} HEAD > _pr_diff.txt codex exec -m "${{ vars.AI_REVIEW_OPENAI_MODEL }}" --full-auto "$(printf '%s' '${{ vars.AI_REVIEW_GUIDELINE_OPENAI }}')" # codex で指示した _pr_comment.md が作られていることを想定している - name: Send comment to PR env: GH_TOKEN: ${{ steps.app-token.outputs.token }} run: | cat _pr_comment.md gh pr comment ${{ github.event.pull_request.number }} --body-file _pr_comment.md
補足
変数とか
vars.CODE_REVIEW_APP_ID: GitHub AppのApp IDを入れてください- https://github.com/organizations/{your org name}/settings/apps/
secrets.CODE_REVIEW_APP_PRIVATE_KEY: GitHub AppのPrivate Keyを入れてくださいvars.AI_REVIEW_OPENAI_MODEL: 使用するOpenAIモデルを指定してください。gpt-5-miniやgpt-5等
vars.AI_REVIEW_GUIDELINE_OPENAI: コードレビューのガイドラインを記入しますsecrets.OPENAI_API_KEY: OpenAI API Keyを入れてください
Codex CLIの制限
ネットワークアクセスが入るコマンドの利用が制限されていて、Codex単体に処理を全て依頼することが難しそうでした。
そのため、 git fetch や git diff をしておき、ファイル差分を事前に出しています。
config.toml に設定を追加すると制限を回避できるみたいな記載があったのですが、うまくいきませんでした。
[sandbox_workspace_write] network_access = true
追加しても↓みたいにいちいち尋ねてきます。私と同じ指示待ち人間。
補足(行コメントの投稿について) - この環境からは GitHub に行コメントを直接投稿できないため、もし必要なら私が作成した「ファイル別の具体的改善案」を行コメント形式で整形して提供します(そのテキストを `gh api` で PR の行コメントとして投稿するか、GUI で貼り付けてください)。行コメントを自動で作るスクリプトが必要なら生成します。 次に私ができること(選択肢) - A) 指摘事項を行コメント形式(ファイル/行指定付き)で出力します。→ あなたが `gh api` で投稿するか、GUIでコピペ可能。 - B) PR 全体のフォーマルなレビュー本文(より詳細)を作成します(そのまま `gh pr review --body` に貼れる)。 - C) 追加で特定ファイルの更に細かいチェック(例: YAML の schema 検証や action 入力/出力の厳密チェック)を行う。 どれを希望しますか?また、私が用意した上の要約をそのまま `gh pr review` 実行してもらって構いません。
なので諦めて、レビューの要旨をMarkdownで出力して、それを手動で gh pr comment で投稿するようにしました。
プロンプトには以下のような文言を追加しています。
**あなたが直接 gh コマンドが使えない場合は、 gitコマンドや github actions の変数から内容を取得することを試みてください**
**コード差分は `git diff ${{ github.base_ref }} HEAD` で取得できるはずで、その結果は `_pr_diff.txt` に既に保存しています**
**レビュー結果をMarkdownファイルとしてカレントディレクトリの `_pr_comment.md` に出力してください。私が `gh pr comment ${{ github.event.pull_request.number }} --body-file _pr_comment.md` と実行するだけでコメントが送信できるようにしてください**
**レビュー結果はMarkdownの機能をフル活用してください。絵文字や太字、Headingやコードブロックを適切に使用してください**
**レビュー結果は結果のみを簡潔に記述してください。結果は「重大な問題」「修正が必要な問題」「確認事項」「推奨事項」のカテゴリに分けて詳細に列挙してください。カテゴリはHeading2を使ってください。結果が存在しない場合は何も記載しないでください**
**最後に安全にマージ可能かどうかのスコア評点を5段階で採点してください**
デバッグのために cat _pr_comment.md を実行コマンドに追加していますが、
今のところはこれで成功しているので抜いても良いかもしれません。
Wrapping up
簡単にできると思ったら、ネットワーク制限設定でつまづき、 最終的に ファイル出力 + 手動実行 という形に落ち着きました。 Workaroundな感じで避けたかったのですが、意外に応用が効くのでこれはこれで良いのかもと思っています。
gpt-5-mini を使っていますが、他のツール・モデルのレビューと比べるとちょっとドライな感じがします。
「絵文字使って」っていってるのに全然使ってくれません。

でも、これはこれでたまりません。ありがとうございます。
関連
前回から同じ内容でコードコピペ + 画像作成するだけだったので経営会議中に1hで書き終わりました。単純作業タスク最高です。
PR
エンジニアの人、助けてください。
GitHub ActionsでGemini CLIによるGitHub PR Reviewを実行する
前回のDevinに続き、 GitHub ActionsでGemini CLIを使ってGitHub PR Reviewをする方法について記載します。
** Disclaimer: 下書きを6/29に9割書いて放置してました。 気づいたら8/15になってました。黒夢のライブも始まっています。タイムマシンで6月末になった気分で閲覧してください。たぶん少し古いです。

背景・雑感
Claude Codeに遅れて、ようやくGeminiもAIエージェント型CLIが出てきました。 ただちょっと探してみたところではそれっぽいワークフローがなさそうなので、強引に設定してみることにしました。 (1ヶ月くらいしたら公式で出てきそうなので、それまでのつなぎの想定)
Gemini CLIは比較的新しく、まだGitHub Actionsとの連携が整備されていない状況です。 とはいえ、CLIツールとして使えるので、GitHub Actionsから直接呼び出すことで自動レビューを実現できます。
tl;dr
↓のような感じで設定するだけ
env: # 0.1.18, 0.1.19だと run_shell_command のエラーが発生するので指定 @2025-08 GEMINI_CLI_VERSION: 0.1.17 jobs: gemini_review: runs-on: ubuntu-latest timeout-minutes: 10 steps: # GitHub App を使う場合は↓、使わない場合は GITHUB_TOKEN を使う(おそらくpermission設定は必要) - name: Generate GitHub App token id: app-token uses: actions/create-github-app-token@v2 with: app-id: ${{ vars.CODE_REVIEW_APP_ID }} private-key: ${{ secrets.CODE_REVIEW_APP_PRIVATE_KEY }} - name: Checkout repository uses: actions/checkout@v4 env: token: ${{ steps.app-token.outputs.token }} - name: Install pnpm uses: pnpm/action-setup@v4 with: version: 10 run_install: false - name: Setup Node uses: actions/setup-node@v4 - name: Install gemini-cli run: | pnpm add -g @google/gemini-cli@${{ env.GEMINI_CLI_VERSION }} - name: Run command env: GH_TOKEN: ${{ steps.app-token.outputs.token }} GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }} run: | gemini -y -m "${{ vars.AI_REVIEW_GEMINI_MODEL }}" -p "$(printf '%s' '${{ vars.AI_REVIEW_GUIDELINE_GEMINI }}')"
補足
変数とか
vars.CODE_REVIEW_APP_ID: GitHub AppのApp IDを入れてください- https://github.com/organizations/{your org name}/settings/apps/
secrets.CODE_REVIEW_APP_PRIVATE_KEY: GitHub AppのPrivate Keyを入れてくださいvars.AI_REVIEW_GEMINI_MODEL: 使用するGeminiモデルを指定してください。gemini-2.5-flashやgemini-2.5-pro等
vars.AI_REVIEW_GUIDELINE_GEMINI: コードレビューのガイドラインを記入しますsecrets.GEMINI_API_KEY: Google AI StudioのAPI Keyを入れてください。
pnpm
pnpmでインストールしていますがかなり早いです。 試行していた際はそのままnpmでインストールすると20~25sかかっていましたが、 pnpmにすると4~5sでインストールできます。早すぎぱない。 もう一生ついていきます。
pnpm add -g @google/gemini-cli
認証方法
Gemini CLIでは3種類の認証方法が使えます:
- Google Auth - Googleアカウントでの認証
- Gemini API Key - Google AI StudioのAPI Keyを使った認証
- Vertex AI - Google CloudのVertex AIを使った認証
最初はVertex AIで使おうとしていたんですが、モデルのデフォルトのQuota が低くてすぐエラーになって使いづらかったのでAPI Keyを使う形にしました。今は解消しているかもしれません。
プロンプト・printf
GitHub ActionsのOrganization variables, secretsにプロンプトを入れていますが、改行やクオートの取り扱いでエラーが出やすかったのでprintfを使って変数を展開しています。
Wrapping up
Gemini CLIを使ったGitHub PR Reviewは、比較的シンプルに設定できました。 他のツールと違い制限が少ないため自由に色々使えると思います。
レビューの精度に関してはまだ微妙な印象で、、プロンプトの工夫が必要かもしれません。

個人的には、PR AgentやDevinと組み合わせて多層的なレビューを行うことで、より効果的なコードレビューが実現できると考えています。 次回はOpenAI Codexでのプルリクレビューについて書きます。
PR
エンジニアの人、助けてください。
GitHub PR Review を自動でDevinにお願いする
お久しぶりです、羅針盤の森川です。
前回の記事から大分時間が経ってしまいました。
そう、それはまるで(以下略)
ということで今回はDevinを使ってGitHubのPRを自動でレビューする方法をご紹介します。

tl;dr
以下のようなAPIリクエストを送信するだけです。
curl -X POST "https://api.devin.ai/v1/sessions" \
-H "Authorization: Bearer $DEVIN_API_KEY" \
-H "Content-Type: application/json" \
-d "{\"playbook_id\": \"playbook-000000000000000000000000\", \"prompt\": \"以下のプルリクエストのコードをレビューしてください。\nPR: https://github.com/your-org/your-repo/pull/123\nレビュー完了後は必ず 'gh pr review' を実行してフィードバックを残してください。\"}"
背景
最近も(GitHub) Copilotでレビュー依頼できるようになっていますが、
羅針盤では元々PR AgentでAIレビューを実行していました。
とはいえ普通に使っているとドメインロジックを前提としたレビューは難しく、わざわざそこの整備にリソースをかけたくはありませんでした。
(進歩が早いので、メンテで苦しんでいる間にGitHubや大手プラットフォーム側で対応する可能性が高いと思っていた)
そんな折、3月末頃にDevinでWiki機能がベータリリースされたので、もっとうまくレビューしてくれるかもという淡い期待を持ちながら自動レビューを追加してみることにしました。
また、DevinのACUsも余り気味だったので 無駄金を捨てている それをもっと活用したいという強いキモチもありました。
前提条件
- Devin Teamプラン以上を契約していること
- CoreプランではAPIが使えず...
設計と実装
ACUsが余っているとはいえ無駄打ちもしたくなかったので、一定の複雑さやコード量があった場合のみ依頼するようにしました。
ここでは既にPR Agentを導入しており、さらにPR Agentで5段階のラベル Review effors x/5 を付与しているので、それを元にDevinに依頼するようにしました。
実行の流れは以下のようになります。
- (1) プルリクエスト作成
- (2) PR Agentによるレビューが実行される
- (3) PR Agentによって3/5以上のReview effortsのラベルが付与された場合に
ai/reviewラベルを追加付与 - (4)
ai/reviewラベルが付与された場合にDevinに依頼
なお、5月中にGitHub Actionsを統一してほぼ全てReusable workflow化しており、実運用しているYAMLと微妙に違うので、動かなかったらごめんなさい;;
1. DevinのPlaybookを作成
Playbooksの設定画面から以下のようなPlaybookを適当に作成します。 (サンプルを元にAIでブラッシュアップしてもらったもの、のはず...)
## 概要 (Overview)
主なタスクは、指定されたプルリクエスト(PR)に対して、徹底的なコードレビューを実施することです。あなたの責任は、コードの変更点を分析し、潜在的な問題を特定し、改善点を提案し、一般的なベストプラクティスおよび(もし提供されていれば)プロジェクト固有のガイドラインへの準拠を確認することです。あなたのレビューは、開発者にとって建設的で、明確で、実行可能なものでなければなりません。あなたはレビューコメントを提供することに専念し、コードの変更、テストの実行、PRのマージは行いません。
## ユーザーから必要な情報 (What's Needed From User)
- レビュー対象のプルリクエスト(PR)のURL。
- (任意)レビューで特に重点を置いてほしい箇所。
- (任意)プロジェクト固有のコーディング規約、コントリビューションガイドライン、または関連するコンテキストへのリンク。
## 手順 (Procedure)
### 1\. 準備とコンテキストの理解
1-1. **PR情報の取得:** 提供されたPRのURLを使用して、PRに関する詳細情報(例: `gh pr view <PR_URL>` を使用)を収集します。PRのタイトル、説明、および関連付けられたIssueを理解し、変更の目的と範囲を把握します。
1-2. **コードのチェックアウト:** PRのブランチをローカルにチェックアウトし(`gh pr checkout <PR_NUMBER>`)、コードを簡単にナビゲートおよび検査できるようにします。比較のためにベースブランチをメモしておきます。
1-3. **差分の分析:** PRによって導入されたコード変更(`git diff <base_branch>...<head_branch>` または `gh pr diff <PR_NUMBER>`)を注意深く調べます。変更されたファイルとセクションを特定します。
1-4. **関連コードの確認(必要な場合):** 変更が複雑な既存システムと相互作用する場合、潜在的な影響を理解し、変更がうまく統合されることを確認するために、周辺のコードを簡単にレビューします。
### 2\. コードレビューの実施
2-1. **体系的なレビュー:** コードの変更をファイルごと、またはコミットごとにレビューします。以下の側面(ただし、これらに限定されません)に焦点を当てます:
- **機能性と正確性:** コードは記載された目的を達成しているように見えますか?明らかなロジックエラー、off-by-oneエラー、または処理されていないエッジケースはありませんか?
- **可読性と保守性:** コードは理解しやすいですか?変数名や関数名は明確で意味のあるものですか?コードが過度に複雑になっていませんか?コメントは適切に使用されていますか(「何を」ではなく「なぜ」を説明しているか)?
- **一貫性:** コードスタイルはプロジェクト内の既存のコードと一致していますか?(フォーマット、命名規則などを考慮)
- **ベストプラクティス:** コードは使用されている言語、フレームワーク、ライブラリの一般的なベストプラクティスに従っていますか?非推奨の機能が使用されていませんか?
- **セキュリティ:** 明らかなセキュリティ脆弱性はありませんか?(例: ユーザー入力の処理、インジェクション攻撃の可能性、認証情報の不安全な取り扱い)_注: これは予備的なチェックであり、重要なアプリケーションには専用のセキュリティ監査が必要な場合があります。_
- **パフォーマンス:** 明らかなパフォーマンスのボトルネックはありませんか?(例: 非効率なループ、ループ内での不要なデータベースクエリ)
- **エラー処理:** エラー処理は堅牢ですか?コードは潜在的な障害を予期し、適切に処理していますか?
- **テスト容易性:** コードはユニットテストを比較的容易に記述できるような構造になっていますか?
2-2. **コメントの作成:** フィードバックをレビューコメントとして準備します。コメントが以下の点を満たしていることを確認します:
- **具体的:** コメントがどのファイルのどの行(複数行)に関するものか明確に示します。
- **明確:** 問題点や提案を簡潔に述べます。
- **建設的:** _なぜ_ それが問題なのかを説明し、可能であれば具体的な改善策や代替案を提案します。フィードバックは丁寧な言葉遣いで行います。
- **実行可能:** 開発者があなたのコメントに基づいて何をすべきかを理解できるようにします。
- **バランス:** うまく実装されている部分を見つけたら、肯定的なフィードバックを残すことも検討します(任意ですが推奨されます)。
### 3\. レビューの提出
3-1. **コメントの投稿:** 適切なツール(例: `gh pr review`)を使用して、GitHub PRに直接コメントを投稿します。コメントは行ごとに、または単一のレビュー提出の一部として追加できます。
3-2. **全体レビューの提出:** PRに対するあなたの全体的な評価(例: 「Approve」(承認)、「Request Changes」(変更要求)、または「Comment」(コメントのみ))を提出します。必要に応じて、最も重要な点を強調する簡単な要約コメントを含めます。
3-3. **ユーザーへの通知:** レビューが完了したことをユーザーに通知します。PRへのリンクを提供し、主な指摘事項や全体的な評価を簡単に要約します。
### 4\. フォローアップ対応(必要な場合)
4-1. **修正内容の再レビュー:** 開発者があなたのフィードバックに基づいて変更をプッシュした場合、問題が満足に対処されたことを確認するために更新内容をレビューします。必要に応じて、追加のコメントや承認を提供します。
## タスク完了の要件 (Task Specification)
- レビューコメントは、GitHub PRの関連するコード行に直接投稿されていること。
- GitHubコメントは具体的、明確、建設的、かつ実行可能であること。
- レビューは、正確性、可読性、一貫性、セキュリティ(基本的なチェック)、ベストプラクティスなどの側面をカバーしていること。
- プロジェクト固有のガイドラインが提供されていた場合、レビューでそれらが考慮されていること。
- GitHubコメントは**自然な日本語で書かれている**こと。
- 全体的な**レビューステータス(Approve, Request changes, Comment)が提出されている**こと。
- レビューステータスの提出は1回のレビューセッションで1度だけ行うこと。複数回行う必要がある場合はまとめて実行するか、前回のコメントをEditすること。
- **指摘事項がなくても全体的なフィードバックをGitHubコメントに投稿する**こと
## 禁止事項 (Forbidden Actions)
- PRブランチのコードを直接**変更しないこと**。
- プルリクエストを**マージしないこと**。
- レビューコンテキストの一部として特に指示がない限り、テストを**実行しないこと**。
- 曖昧で役に立たない、または攻撃的なコメントを**しないこと**。
- PRへのレビューコメント追加の範囲を超えて、リポジトリに**いかなる変更も加えないこと**。
- 重大な問題が未解決のままPRを**承認しないこと**(明示的に指示された場合を除く)。
## ヒントと推奨事項 (Advice and Pointers)
- 効率化のためにGitHub CLI (`gh`) を積極的に活用すること:
- `gh pr view <PR_URL>`: PRの詳細を表示。
- `gh pr checkout <PR_NUMBER>`: PRブランチをチェックアウト。
- `gh pr diff <PR_NUMBER>`: 差分を表示。
- `gh pr review <PR_NUMBER>`: レビューを提出。行コメントには `--comment`、要約には `--body` のようなフラグを使用。
- 例: `gh pr review <PR_NUMBER> --comment "ここにもっと説明的な変数名を使用することを検討してください。" --line <行番号> --path <ファイルパス>`
- 例: `gh pr review <PR_NUMBER> --request-changes --body "全体的には良好に見えますが、エラー処理と可読性に関していくつかの点に対処しました。特に \`var a = b;\` は \`const a = b;\` への置き換えを検討してください。その他はインラインコメントを参照してください。"`
- `gh pr review` 実行時のMarkdown記述に含まれるバッククォート(`) はリクエストが正常に送られるように必ずバックスラッシュでエスケープ (\'foobar\')すること。
- 明らかに正しい修正差分を考えついた場合はGitHubコメントの提案機能を使うこと。
- 特に関数コメント・メソッドコメントが付いていなかったり、他からのコピペでコメントが間違っている場合はコメント提案をしてあげること。
- 変更を提案する際は、その提案の背後にある理由を説明すること。
- コードの一部について意図が不明な場合は、コメントで明確化のための質問をすること。
- フィードバックに優先順位をつけること: マイナーなスタイルの指摘よりも、最も重要な問題(例: 正確性、セキュリティ)にまず焦点を当てること。
- レビューに関連するコンテキストを提供する可能性のある、リポジトリ内の既存のドキュメント(`README.md`、`CONTRIBUTING.md`、 `.cursor/*`、スタイルガイドなど)を確認すること。
- PRのスコープ(範囲)を意識すること。現在の変更がそれを必要としない限り、関連性のない大規模なリファクタリングを提案することは避けること。
2. ラベル付与時にDevin APIを呼び出すワークフロー
まずは ai/review というラベルがPRに付与された際に発火して、
Devin APIを呼び出すGitHub Actionsのワークフローを作成します。
name: "[PR] Devin Review" on: # プルリクエストにラベルが付与されたときにトリガー pull_request: types: [labeled] env: label_name: ai/review playbook_id: playbook-0000000000000000 jobs: request_devin_review: runs-on: ubuntu-latest permissions: pull-requests: write issues: write steps: - name: Request Devin Code Review # 指定されたラベルが付与されている場合のみ実行 (i.e. `ai/review`) if: ${{ github.event.label.name == env.label_name }} env: DEVIN_API_KEY: ${{ secrets.DEVIN_API_KEY }} PR_URL: ${{ github.event.pull_request.html_url }} run: | JSON_PAYLOAD=$(cat <<EOF { "playbook_id": "${{ env.playbook_id }}", "prompt": "以下のプルリクエストのコードをレビューしてください。\nPR: ${PR_URL}\nレビュー完了後は必ず 'gh pr review' を実行してフィードバックを残してください。" } EOF ) curl -X POST "https://api.devin.ai/v1/sessions" \ -H "Authorization: Bearer $DEVIN_API_KEY" \ -H "Content-Type: application/json" \ -d "$JSON_PAYLOAD"
これで手動で ai/review ラベルを付与するとDevinに依頼できるようになりました。
3. PR Agent側で Review efforts x/5 ラベルが付与された際に ai/review ラベルを付与するワークフロー
次にPR Agentと組み合わせて、 Review efforts x/5 ラベルが付与された際に ai/review ラベルを付与するワークフローを作成します。
ここでは 3/5以上のラベルが付与された場合に ai/review ラベルを付与するようにします。
name: "[PR] PR Agent" on: pull_request: types: [opened, reopened, ready_for_review] issue_comment: types: [created] permissions: issues: write pull-requests: write id-token: write env: ai_review_label_name: ai/review jobs: pr_agent_job: # bot によるPR作成・コメントはスキップ if: ${{ !endsWith(github.actor, '[bot]') }} runs-on: ubuntu-latest timeout-minutes: 8 name: Run pr agent on pull request steps: - id: "auth" uses: "google-github-actions/auth@v2" with: # ※ ここではOIDC認証にしてますが、年始くらいからVertexAIの動作がバグってるので今はService Account JSONを使っています。(LiteLLMにうまくプロジェクトIDが渡せてなさそう) # あと気になる人は project_id とかにsecrets使ってください workload_identity_provider: projects/000000000000/locations/global/workloadIdentityPools/github-actions-pool/providers/github-actions-provider service_account: github-vertex-ai-pull-request@example.iam.gserviceaccount.com project_id: example access_token_lifetime: 400s - name: PR Agent action step id: pragent uses: Codium-ai/pr-agent@main env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} GITHUB_ACTION_CONFIG.AUTO_REVIEW: true GITHUB_ACTION_CONFIG.AUTO_IMPROVE: true PR_REVIEWER.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} PR_DESCRIPTION.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} PR_CODE_SUGGESTIONS.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} PR_CODE_SUGGESTIONS.NUM_CODE_SUGGESTIONS: 3 PR_ADD_DOCS.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} PR_UPDATE_CHANGELOG.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} PR_TEST.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} PR_IMPROVE_COMPONENT.EXTRA_INSTRUCTIONS: >- ${{ vars.PR_AGENT_INSTRUCTION_COMMON }} # モデル設定(コスパ重視 & 完了が早いのでGemini 2.5 Flash) CONFIG.MODEL: ${{ vars.PR_AGENT_MODEL }} CONFIG.MODEL_TURBO: ${{ vars.PR_AGENT_MODEL }} CONFIG.FALLBACK_MODELS: ${{ vars.PR_AGENT_MODEL_FALLBACK }} # VERTEXAI.VERTEX_PROJECT: example pr_labeler: needs: pr_agent_job runs-on: ubuntu-latest steps: # pr_agent_jobによって pull_request のラベル に 'Review effort [1-5]: 3' 以上のラベルが付与されているかチェック # PR Agentのバージョンによる仕様差異のせいか形式が `[1-5]: 3` だったり `3/5` だったりしていたので、両方入れてます - name: Check current label id: label_result uses: actions/github-script@v7 with: script: | const labels = await github.rest.issues.listLabelsOnIssue({ owner: context.repo.owner, repo: context.repo.repo, issue_number: context.issue.number }) console.log(labels.data) validLabels = { 'review effort [1-5]: 3': true, 'review effort [1-5]: 4': true, 'review effort [1-5]: 5': true, 'review effort 3/5': true, 'review effort 4/5': true, 'review effort 5/5': true, } for (const label of labels.data) { const s = label.name.toLowerCase() if (s == '${{ env.ai_review_label_name }}') { return "false" } if (validLabels[s]) { return "true" } } return "false" result-encoding: string - name: Add '${{ env.ai_review_label_name }}' label uses: actions/github-script@v7 if: ${{ steps.label_result.outputs.result == 'true' }} with: # ここには任意のGitHubトークンを設定してください。 # Fine-graded Tokenの権限は `Pull requests` の Read and write が必要です。 # ※ PRデフォルトの secrets.GITHUB_TOKEN を使うと後続のワークフローが発火されない github-token: ${{ secrets.GH_TOKEN_FOR_LABEL }} script: | github.rest.issues.addLabels({ owner: context.repo.owner, repo: context.repo.repo, issue_number: context.issue.number, labels: ['${{ env.ai_review_label_name }}'] })
Wrapping up
これでPRに ai/review ラベルが付与された際にDevinに依頼できるようになり、
PR Agentが自動的に Review efforts x/5 ラベルを付与してくれ、3/5以上のラベルが付与されたPRに対してDevinに依頼できるようになりました。
弊社の環境だと消費ACUsは大体0.6前後になることが多く、多いときは1.x程度になります。
レビュー観点という意味では価値がありますが、個人的には精度はまだまだ満足いくものではなく、
もっと固有のドメイン知識から指摘をして欲しいと思っています。
ドキュメント・Wikiをもっと整備すれば良いのかもしれませんが、
この辺りはDevinに限らず、1年以内に勝手に対応して自動的に解消するのではないかと楽観的に思ってます。
PR AgentやCopilotのレビューに引きづられている印象を受けるので、プロンプト・Playbookで改善する部分もまだまだありそうです。
とりあえず PR Agent (Gemini 2.5 Flash) + Copilot + Devin の3つでレビュー依頼していて、 それぞれ微妙に違った観点でレビューしてくれていて、どれかが見逃したものを指摘してくれることもあるので、多層構造というかセーフティネット的な役割を果たしてくれていると感じています。
あまりチューニングできていないので、いい感じのPlaybookができたらぜひ教えていただけると我々万歳百唱で喜びます。